Analyzing World of Tanks Blitz
I don't know much about statistics. I don't know much about R either. I'm not a pro of Python. But I want to practice all that. And more specifically, I want to level up my stats skills.
Okay, but... World of Tanks? why?
# World of Stats
World of Tanks: Blitz is a free to play mobile MMO game. The rules are quite simple: You drive a tank, two teams of seven players fight each other until one team wins or the time limit of 7 min is reached: the game is then a draw. I don't particularily want to speak about the game itself, but it'll be a great source of data to play with: People playing it happen to be obsessed with their stats, and tend to take the game quite seriously.
Wargaming, the company that created the game, provides an API, which means that we can send requests to their server to get informations about Players, and, in particular, their precious Win Rate.
# Python Setup
As I said, I'm not a pro of python, so I might not write a beautiful pythonic code, but I'll try to get it as clean as possible. I'm going to use python 2, because I'm more used to it, and because we won't need any Python3's new functionnalities.
# sending requests in Python: urllib
There are several libs that one can use to send http requests, but urllib will be enough for our task.
urllib2 is another packages that offers different functionalities, and requests is a packages that helps on writing more complex applications.
I'll only need to send a simple GET request and to read the answer from the server:
import urllib
response = urllib.urlopen('url/to/open').read()
urlopen returns a file-like object, and the read() function reads the entire content and turns it into a single string. the variable response contains the server response.
In our case the server will return some JSON data, for example if we search for a player named 'Player0000000001' we would get:
{
"status": "ok",
"meta": {
"count": 1
},
"data": [
{
"nickname": "Player0000000001",
"account_id": 532789529
}
]
}
after the read() call we only get a string, so we need to parse it from JSON, that will give us a python dictionnary:
import json
js = json.loads(response)
And that's all! After that we can play with our data to get what we want from it.
# Creating our requests
We want to get as much data as possible, from as much different players as possible. The trick is, the API doesn't provide a way to do it easily.
We can search for a nickname, but this won't be a good solution in our case. We need to find a more reliable way to search for any registered account.
# finding accounts
The accounts have an id number that we could use: after looking at some random accounts with the nickname search from the api, we get random ids that show us where to search:
id
521186521
528592939
520337689
531942985
525816285
530570469
529238831
527453682
520523798
525728616
529244059
528602095
525776411
506144415
528539103
532136510
523093470
...
Let's do our first plot with R from these data!
# read the csv file
data <- read.csv('~/Documents/accounts_sample.csv')
# don't use scientific notation on axis
options(scipen=5)
# plot the graph
hist(data$id,breaks=100)
this gives us the following plot:
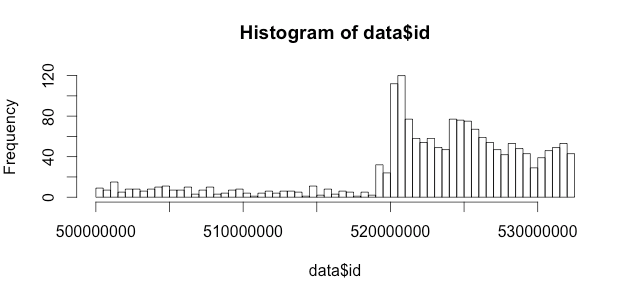
So we can see that we should search for ids from 520000000 to get better results: we will send requests for all ids we can, but not all numbers correspont to a valid account, so we have to find the most promising numbers.
# requesting IDs
Now that we know what we're looking for, let's actually create the requests!
The syntax of the requests on the server to get informations about a player from it's ID is as following:
https://api.wotblitz.eu/wotb/account/info/?application_id=my_secret_token&account_id=the_id_we_want
and the answer will look like this:
{
"status": "ok",
"meta": {
"count": 1
},
"data": {
"520758690": {
"last_battle_time": 1448942331,
"account_id": 520758690,
"created_at": 1404759853,
"updated_at": 1448942360,
"private": null,
"statistics": {
"clan": {
[stuff...]
},
"max_xp_tank_id": 8737,
"max_xp": 2703,
"company": {
[stuff...]
},
"all": {
"spotted": 45956,
"max_frags_tank_id": 9217,
"hits": 210398,
"frags": 34714,
"max_xp": 2703,
"max_xp_tank_id": 8737,
"wins": 17159,
"losses": 13478,
"capture_points": 25840,
"battles": 31594,
"damage_dealt": 48995152,
"damage_received": 35609321,
"max_frags": 7,
"shots": 260256,
"frags8p": 18303,
"xp": 21513200,
"win_and_survived": 11290,
"survived_battles": 12011,
"dropped_capture_points": 71478
},
"team": {
[stuff...]
},
"frags": null
},
"nickname": "MikakeSensei_warrior"
}
}
}
I've removed parts of the data that we won't use.
I decided to keep the ID , nickname, creation date, last battle time (in order to have some way to know wether the player is active or not) , max_xp (best result in a battle) , number of battles and wins (to get the win rate).
We can change our request accordingly by telling the parameters we want:
[url] &fields=account_id%2Cnickname%2Ccreated_at%2Cstatistics.max_xp%2Cstatistics.all.battles%2Cstatistics.all.wins%2Clast_battle_time
(I just added '&fields=' and then the fields I wanted, separated by '%2C', which is a comma)
and I get a much cleaner answer:
{
"status": "ok",
"meta": {
"count": 1
},
"data": {
"520758690": {
"created_at": 1404759853,
"statistics": {
"all": {
"wins": 17159,
"battles": 31594
},
"max_xp": 2703
},
"nickname": "MikakeSensei_warrior",
"account_id": 520758690,
"last_battle_time": 1448942331
}
}
}
# Storing the data
We will store the data in the csv format, because it will keep the implementation as easy as possible and provide a good flexibility for reusing the data later on.
our goal is to get this kind of file:
id,nickname,creation,last_battle,max_xp,battles,wins
520000000,Kubafghoplolzax,1403789966,1403793272,205,9,4
520000001,Olegator180,1403789966,1408536283,610,52,33
520000007,himynameia,1403789987,1403790450,120,2,1
520000008,pobejali,1403790076,1404586588,311,6,3
520000009,AdrianK2000,1403789985,1404387161,870,152,71
520000010,xjanox_1,1403789986,1403876801,97,7,2
520000011,Ipozaup,1403789986,1403790274,37,1,0
520000012,piamolym,1403789992,1403944689,34,2,0
520000017,gorin059,1403790083,1403791894,16,1,0
520000018,steeLovic1,1403790003,1403790465,229,1,1
520000019,hungryappuser,1403790006,1404048877,442,17,7
As you can see, these data are the actual results from the search starting ad 520000000 , the ID I decided to start with by looking at the earlier plot.
You may also notice that as we expected, not all IDs correspond to an existing account. so we need to see what the server answer is when we request a wrong account number:
{
"status": "ok",
"meta": {
"count": 1
},
"data": {
"520000002": null
}
}
Pretty easy, the data will just contain "null" for the concerned account ID.
# Lots of requests
Now we have everything we need to create a nice little script that will request IDs and save the informations we want into a file.
# One request
Let's begin with one request.
We want to create our json from the request's result:
Import the libraries,
import urllib
import json
Prepare the query's url
token = '*****secret_token*****'
base_request = 'https://api.wotblitz.eu/wotb/account/info/'
+'?application_id='+token
+'&fields=account_id%2Cnickname'
+'%2Ccreated_at%2Cstatistics.max_xp'
+'%2Cstatistics.all.battles%2Cstatistics.all.wins'
+'%2Clast_battle_time'
+'&account_id='
id = '520758690'
GET the data
data_str = urllib.urlopen(base_request+id).read()
data_json = json.loads(data_str)
Format them as we want
data = data_json['data'][id]
data_csv = ",".join([
str(data['account_id']),
data['nickname'],
str(data['created_at']),
str(data['last_battle_time']),
str(data['statistics']['max_xp']),
str(data['statistics']['all']['battles']),
str(data['statistics']['all']['wins'])
])
At the end of this program, we end up with a data_csv variable that contains the informations about the id :
>>> data_csv
id,nickname,creation,last_battle,max_xp,battles,wins
u'520758690,MikakeSensei_warrior,1404759853,1448942331,2703,31594,17159'
# One Hundred requests
We can almost see how we'll get our data. Except sending one request per account ID would be very very long and server intensive.
Fortunately we can send up to 100 accounts IDs per request to the server, with the same syntax as when we specified the fields:
&id=first_account%2Csecond_account%2Cthird_account
this will be of great help, now we can change our script to get all account information in a range of 100:
first let's look at how python allows us to create a string of the desired format from a range of numbers:
comma='%2C'
begin=520000000
list_id_str = comma.join([str(i) for i in range(begin,begin+100)])
to explain this a little bit:
- range(a,b) creates a array containing integers from a to b (exclusive)
- Python's list comprehension allows us to turn each number into a string
- the join method takes an array and returns one string containing all array elements, separated by the string (comma in our case)
and the answer we will get from the server will be:
{
"status": "ok",
"meta": {
"count": 1
},
"data": {
"first_ID": [null or account's data ...],
"second_ID": [null or account's data ...],
"third_ID": [null or account's data ...],
# [...]
"hundredth_ID": [null or account's data ...]
}
}
So, if we create a function that extracts the data we want and turns it into a string of comma-separated values:
def extract_data(data):
return ','.join([
str(data['account_id']),
data['nickname'],
str(data['created_at']),
str(data['last_battle_time']),
str(data['statistics']['max_xp']),
str(data['statistics']['all']['battles']),
str(data['statistics']['all']['wins'])
])
we will be able to apply it very easily to our server response:
id_list = range(begin,begin+100) # the array
id_list = [str(i) for i in id_list] # turn integers to strings
id_list_str = comma.join(id_list) # for the http GET request
data_str = urllib.urlopen(base_request+id_list_str).read()
data_json = json.loads(data_str)['data']
csv_list = [extract_data(data_json[i]) for i in id_list]
That's great. We're almost done!
We need to handle the case where the account ID is not in use. Python provides a nice way to filter items in a list comprehension:
csv_list = [extract_data(data_json[i]) for i in id_list if not data_json[i]==None]
We simply add the condition as the third section of the list comprehension. Note that None is python's word for 'null'
And here is what I get for the 100 first requests:
520000000,Kubafghoplolzax,1403789966,1403793272,205,9,4
520000001,Olegator180,1403789966,1408536283,610,52,33
520000007,himynameia,1403789987,1403790450,120,2,1
520000008,pobejali,1403790076,1404586588,311,6,3
520000009,AdrianK2000,1403789985,1404387161,870,152,71
520000010,xjanox_1,1403789986,1403876801,97,7,2
520000011,Ipozaup,1403789986,1403790274,37,1,0
520000012,piamolym,1403789992,1403944689,34,2,0
520000017,gorin059,1403790083,1403791894,16,1,0
520000018,steeLovic1,1403790003,1403790465,229,1,1
520000019,hungryappuser,1403790006,1404048877,442,17,7
520000020,RcuT,1403790004,0,0,0,0
520000027,ssolo_way,1403790225,0,0,0,0
520000028,prendy00,1403790031,1403815059,13,1,0
520000031,henrymetz,1403790044,1426773292,211,11,2
520000034,Designerl,1403836925,1403877082,310,3,3
520000037,yahon1,1403790204,1405743130,220,5,2
520000038,Dhsnddid,1403790070,0,0,0,0
520000040,VencaM3,1403790077,1403804368,286,8,5
520000043,CWeeksy,1403790086,1403790451,34,1,0
520000045,MarcoMandelli,1403790086,1406907621,854,303,159
520000050,ironmetal83,1403790107,1403790451,13,1,0
520000052,r4m0nster,1403790108,1441209616,1527,1183,602
520000053,ROM123_winner,1403790111,1403852832,109,3,1
520000055,Akhy,1403790117,0,0,0,0
520000060,COBRA49_Steph,1403790385,1404231441,164,7,1
520000062,Skywot,1403790144,1405934171,612,195,89
520000065,max332,1403790148,1410420198,697,73,36
520000066,poohjinwook,1403790151,1403791354,151,2,1
520000068,knex3,1403790152,0,0,0,0
520000069,Hodymody,1403790151,1448648111,652,246,115
520000070,steadyPL_2014,1403790152,1412437978,724,87,47
520000072,sicWel,1403790155,1405913658,847,111,59
520000073,kinkin_2014,1403790159,1404822188,208,13,2
520000075,dumareckii,1403790287,1403894809,501,25,10
520000077,sedlo4,1403790167,1403958570,155,3,2
520000079,Maragas,1403790169,0,0,0,0
520000080,Benzema_1,1403790176,1403790465,101,1,1
520000081,judda,1403790231,1429253327,984,114,55
520000087,Tomitor5,1438795494,1446017465,553,78,23
520000088,CharlES_season2,1403790189,1421573900,398,58,25
520000090,ducuoekeivjr,1403790189,1403803630,141,4,2
520000091,xXxBeast_KillerxXx,1403790191,1403791019,419,2,1
520000095,Kainit,1403790246,0,0,0,0
520000098,overclass112,1403790209,0,0,0,0
# Thousands of requests
With a little improvements we can easily get a fully working application that explores as many accounts as we want and save them all on a file
I let this working from 520000000 to 532626648 , and I got 5,073,693 accounts from it! It took quite a lot of time to complete, and the text file is 263MB large :)
In the next post we'll see what we can get from this huge data!